How to use crontab utility from X?
How to edit crontab utility from GNOME or KDE?
How to have a GUI-based utility with GUI desktop interface?
How to have a GUI task scheduler?
How to install KDEAdmin?
How to install KCron with Fedora 7?
From recent blog entry about crontab utility found here and here, here's an entry on how to utilize crontab utility with non-terminal GUI desktop interface?
KCron is a GUI application for managing cron schedules interactively using a friendly-user GUI-based desktop interface. In other words, KCron is a graphical user interface to cron system scheduler called cron utility. This KCron package is only one of the many binaries included from KDE administration component. KCron can be installed and executed both under the GNOME and KDE environment.
INSTALLATION
~~~~~~~~~~~~~~
Kcron GUI-based cron scheduling utility can be installed also using yum.
# yum -y install kdeadmin
BINARY LAUNCH: Ctrl+F2, kron
During binary launch, KCron scans all system and account users together with all listed and scheduled system and user cron jobs present from the current linux box. KCron displays these cron jobs in a nice and desktop interface. Ease of use and user-friendliness were highly utilized on designing KCron feature for managing scheduled cron jobs. In fact, Kcron is quite attractive and desktop enticing especially for linux newbies who are used to administering jobs with X from their boxes.
By choosing a particular system or user account(s) from the main Kcron screen, Kcron main window presents you mouse-driven options on modifying existing cron jobs of a currently selected user or system accounts. These also include global wide cron jobs from /etc/crontab, /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, /etc/cron.monthly cron files.
Here are the actual screenshot I have on editing and modifying existing cron job. KCron displays all system and user accounts with all their existing cronjobs in a manageable, attractive and easy to use KDE layout using dropdown tree menus and multiple panel and child windows.
Noticeably, Kcron uses KDE power of visual display on accomplishing same crontab job function from a running GUI-enabled linux desktop.
This entry is not here to discredit any default crontab administration and management that comes from any linux distro.
Get Fedora

Friday, August 31, 2007
KCron - GUI task scheduler
Linux backups powered by Tar
Make backups of your data.
Anybody who manages servers usually does administrative server backup procedures on regular repeated basis. There are several wide procedures and approaches on doing data backups. As to which specific data to do the back up depends on the reasons why the need to backup these files and folders.
There are lots of storage options and backup destinations to choose from nowadays. Selecting backup storage types is as logical as where to have backup destinations and what is available on ground. There are people who does their backups from real work or several occasions into their external tape and/or zip drive devices, external and portable large-capacity USB drives, avilable backup servers, removable backup SCSI harddisk, network SAN drives or even flash drive. The interval basis of doing the backup also depends both from server and end-users data operation as well.
Backup procedures also comes down from simple linux backup commands, from non-interactive shell scripts up to commercial backup products.
Bottomline is that these backup techniques and strategical methods depend on what do you have and what is available on ground.
This document entry however covers a foundation approach and mostly used tar arguments on backing up data using the linux command tar.
=============================================
Data backup samples using Tar Linux command
=============================================
A very simple usage of tar
# tar cvf backup.tar *
Legend:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-c create a new tar file
-v verbose mode
-f select file
* file glob selection
By default, tar digs down into subdirectories
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Making it as a backup copy is as simple as moving to a different location. Preferably to another storage location. As discussed earlier, strategical backup methods depends on what is on ground. If you do not have any more available host, or external backup devices. And what you have is another removable or separate harddisk, you can transfer and copy the backup file on that separate or removable harddisk.
If you wish to copy it on a separate disk mounted on a separate partition, that is just simple file copying linux command like so
# cp backup.tar /mounted/separate/harddisk/backup.tar
If you wish to copy your backup file to a mounted external USB or flash device, similarly it would be done like so
Assuming that the external drive is already mounted
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# cp backup.tar /mnt/usb
Alternatively,
# cp backup.tar /dev/sdb1
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Copying data between host to host can be done in many way. One way to achieve this is making use of shell secure copy named scp. If you wish to copy files between two host as tar file, this is more likely how to approach that issue
# scp -C backup.tar username_from_other_host@other_host:destionation_location
# scp -Cpv backup.tar username_from_other_host@other_host:destionation_location
Remember, linux gives us total control using compounded linux commands like so
# scp -C `tar cvf backup.tar *.mp3` remoteuser@remotehost:~remoteuser
Alternatively
# tar cvf backup.tar *.mp3 | scp -C backup.tar remoteuser@remotehost:~remoteuser
Or
# scp -C $(tar cvf backup.tar *.mp3) remoteuser@remotehost:~remoteuser
The above command would prompt you for user's password coming from host destination.
Legend for scp:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-C enable compression mode during data trasfer
-p enable modify and access time and modes from the source original file
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
From this backup files, they might grow into big filesizes eventually. If you wish to burn them into CD/DVD disks, you might do so.
However if you wish to have backup file not as it is but as an ISO image file before any host to host or harddisk to harddisk transfers, this could be done like so
# mkisofs -o myhostname-backup-image01.ISO backup.tar.gz
Then proceed with data transfer of backup files.
More information on creating an ISO image from your big backup archived file, you can read more on creating ISO from recent entry here. DVD/CD burning applications were also discussed from here.
Tar comes with many arguments. Some of them cannot really be combined anytime like create a new tar file while updating or listing archived files. You can have more tar argument sample, below are more working tar samples.
Another tar backup example using more tar arguments:
# tar cvfp backup.tar * --exclude=*.mp3 --no-recursion
# tar zcvfp backup.tar.gz * --no-selinux
# tar zcvfp backup.tar.gz *
# tar jcvfp backup.bz2 *
Legend:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
--exclude exclude file globbing patterns
-z integrate with gzip command, compression on the fly
-j integrate with bzip2 command, compression on the fly
-p preserve permissions
-c create a new tar file
-v verbose mode
-f file selection
* file glob selection
--no-selinux do not include SELinux security context information and extraction date
--no-recursion do not recurse into subdirectories
By default, tar digs down into subdirectories recursively
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If you wish to exclude a directory folder from being archived using tar
# tar cvfp backup.tar * --exclude=FOLDERNAME
From the above examples, --exclude argument was specified since I am currently working on same folder location where
the archived tar file is also being saved and processed.
If you wish to update an existing tar file from new file changes or newly added folders, follow like so
# tar uvfp backup.tar * --exclude=backup.tar
# tar uvfp backup.tar * --exclude=*.tar
From above sample, any file changes and updates would by sync to an existing archived tar file excluding changes occuring from the backup file itself. If the archived file is already existing, the file would be overwritten.
Legend:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-t list down archived files and folder
-u update an existing tar file
--exclude exclude file globbing pattern
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Exclude argument excempts a matched file globbing pattern. From the above example, backup.tar and anyfile that ends with tar file extension (*.tar) would not be updated with the last tar command.
If you wish to exclude batches of files without filename patterns, you can create a text file that contains the filenames that needs to be excluded from the tar operation like so
# cat except.txt
~~~~~~~~~~~~~~~~~~~~~~
filename1.mp3
batibot.ISO
sesame.tar.gz
....
snipped
....
~~~~~~~~~~~~~~~~~~~~~~
and feed it to tar operation command with -X tar argument like so
# tar cvfp backup.tar * -X except.txt
# tar cvfp backup.tar * -X except.txt -X except2.txt
If you wish to append a new set of files or folder to an already existing tar archive, using tar would be
# tar rvfp /home/oldfolder/backup.tar /home/newfolder
# tar rvfp /home/oldfolder/backup.tar /home/newfolder/folder1/*
If you wish to backup a floppy disk using tar, you could do like so
Mount the floppy disk first like so
# mkdir /mnt/floppy
# mount /dev/floppy /mnt/floppy
And tar all contents from floppy disk like so
# tar cvfp floppy.tar /mnt/floppy/.
If you wish to backup a CD disk using tar, you could do like so
Mount the CD disk first like so
# mount /dev/cdrom /mnt/cdrom
# tar cvf CDfiles.tar /mnt/cdrom
If you wish to backup the entire harddisk partition
# tar zcvfp home_partition_backup.tar.gz /mounted/partition
# tar zcvfp home_partition.tar.gz /mnt/home
Tape backup using tar is likely the same as shown below
# tar zcvfp home_partition.tar.gz /dev/st0
USB flash drive for small data tar backup can be done like so
# tar zcvf *.doc /mnt/usb1
Multiple tar file concatenation can also be done from tar to back up multiple tar files like so
# tar Afvp home1.tar home2.tar
If you wish to tar all file glob matched from multiple directories and/or tar dynamic matched files from doing find linux command would be like so
# tar zcvf backup.tar.gz `find /home -name '*.txt'`
# tar zcvf backup.tar.gz `find /etc -name '*.conf'`
Incremental Backup or Archiving using Tar
-----------------------------------------
# tar cvfGp incremental-backup.tar *.txt
# tar cvfGp incremental-backup.tar /home/foldername
Alternatively using a date of reference on incremental backup would be like so
# tar cvfGp incremental-backup.tar *.dat -N '1 Sep 2007'
The above command would do incremental backup tagging all *.dat files having file date stamp creations newer than 1st of September 2007.
# tar cvfGp incremental-backup.tar *.dat --newer-mtime '1 Sep 2007'
The above command would process incremental backup tagging all *.dat files with a newer file date modification value than 1st of September 2007.
Verification Listings of Archived Tar file
------------------------------------------
If you wish to list down or verify files inside an archived backup tar file
# tar tfv backup.tar
If you wish to verify a specific file, folders or multiple files if they are listed from particular archived tar file
# tar tfvp backup.tar | grep specificfile.txt
# tar tfvp backup.tar | grep 'file1\|file2'
# tar tfvp backup.tar | grep 'folder1'
Considering thousands listings of archived files from a single tar file and you wish to exclude a folder from being listed, you can optionally use the --exclude tar argument like so
# tar tfvp backup.tar | grep 'folder1' --exclude=THISFOLDER
# tar tfvp backup.tar | grep 'folder1' --exclude=*.mp3 --exclude=FOLDERNAME
Extraction of files from an Archived Tar File
---------------------------------------------
For basic extraction of archived tar file
# tar xvf backup.tar --no-recursion
For extraction of gzipped compressed archived tar file
# tar zxvf backup.tar
For extraction of bzipped compressed archived tar file
# tar jxvf backup.tar
For extraction of archived tar file to a specific destination folder
# tar xvf backup.tar -C /tmp
# tar jxvf backup.tar -C /tmp/test
# tar zxvf backup.tar -C /home/sesame
# tar zxvf backup.tar -C /home/sesame --overwrite --overwrite-dir
Legend:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
--overwrite simply overwrites any existing files
--overwrite-dir simply overwrites any existing directory folders
--delete be careful with this one as it deletes the archived tar file after extraction
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Integration of tar backup procedure with shell scripts
-------------------------------------------------------
Doing the backup can be done non-interactively or on automatic mode. The first step to do this is to create a shell script. From there you can list down all the necessary backup tar commands one line at a time and make the script executable. A very basic sample of backup scripts would be combination of tar commands specific to your needs that suits the required files and folders to be back up.
Sample simple backup script
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#/bin/bash
# backup scripts basic examples
# Go to backup or temp folder
cd /tmp
# what is happening?
echo Starting the backup process...
# Do all tar backup lines below
tar zxvfp backup.tar.gz /home --exclude=*.ISO --exclude=*.tar
tar zxvfp backup.tar.gz /home/www/pages
# Make a copy from here to there
cp backup.tar.gz /mnt/separate/hardisk/or/any/mounted/device
# Transfer the backup file from host to host
# Remember an entry with passwordless / passphraseless ssh connection discussed recently?
scp -Cp backup.tar.gz user@hostname:~user
# Gone with the wind, now delete footprints in the sand to save local disk space
rm -rf backup.tar.gz
# I see
echo Done
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If this helps you out somehow, try contributing from the linux bar's tip using those black ninja boxes if you may.
File Naming Convetions
----------------------
One good practice on administering backup files is a good filename convention. This is mostly applicable on handling and processing any type of files from any file read/write operations.
Yes we need a unique filename. A unique file name is required for a repeated backup routines. Linux can generate unique random characters and numbers but the problem with that approach is unique identification of each filename is not identifiable against each other filenames.
What else could we use on unique filename for our backup files.
Ding! A date string value is always unique and usable on daily backup operations as well as time string value would be acceptable as a unique filename for hourly backup operations. Below are examples of unique file naming convention based on current system date and time. This approach is logical in manner of having proper identification among group of backup files.
This date string command was also recently discussed from INQ7.
Example of how to use from shell script
# cat shellscript.sh
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#/bin/bash
ID=`date "+%m-%d-%Y"`
# Daily backup routine with daily unique file name
tar zcvf webpages-$ID.tar.gz /home/www
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# chown 700 shellscript.sh
Unique filename based on date value from command line terminal using tar command would be like
#tar zcvf home1-folders-`date "+%m-%d-%Y"`.tar.gz /home/www
Another unique filename based on time and date values done from terminal would be like
#tar zcvf www-2-pages-`date "+%m-%d-%Y-%I-%M-%S-%P"`.tar.gz /var/www/html2
Backup Scheduling Using Crontab Utility
---------------------------------------
Combining your backup script commands or scripts into linux crontab utility is required for a nice scheduled backup procudures done non
-interactively and automatically on regular basis. There was a recent crontab howto discussion, you can find it here.
There are companies that do their backup during morning hours as most data transaction occurs on night hours. Several do it during sleeping hours or midnight time. But usually, most backup operations depends on each data backup requirements, cut-off date and time implemented by company policies.
Final Note:
Data backups are SOPs, not only for the reason of serving as a fallback data source, but also for serving as history log records and for future references.
Backup data are just dead 1's and 0's of the past, but in one linux snap, they can be brought back to life when we needed them most.
So goodluck, that's it for now.
Unfortunately, screenshots on how a commercially known Tivoli Storage backup system works with linux would not be here.
Next entry would be backing up files using linux rsync and rsnapshot.
Have a nice weekend!
Related Posts:
Linux Backup using RSnapShot
Linux Backup using RDiff
Bandwidth-Effificent and Encrypted Linux Backup
Thursday, August 30, 2007
INQ7 front page image retrieval
According to statistics, the most important page of a newspapager is the frontpage. The very first page of a newspaper is where major news are being emhpasized, given attention, and sensationalized since this is the very outside cover and first entry of attraction where consumers look at from daily newspaper.
With that, INQ7, a website of one of the major newspaper source from Philippines, provides an soft copy of its front page publicly posted from their website on daily basis for the consumer to take a view.
This entry basically covers a simple approach on how to parse date string using linux date command inside a bash shell script to retrieve a front page image of a newspaper particularly from INQ7. This image has a changing filename based from date when the image was photo scanned.
Say the actual URL is
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
http://images.inquirer.net/img/thumbnails/new/hea/pag/img/2007/08/20070830.jpg
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
From the above, the image filename is 20070831 in JPG file format. Noticeably, the folder location is also dynamic in value which is also based on current date
Here's the actual simply bash script on handling this kind of dynamic URL source and image filename based on current date string value.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#!/bin/bash
# script to retrieve front page image from INQ7 website
# get date, year and month in this format: year=2007, month=08, and day of the month=30
date=`date "+%Y%m%d"`
year=`date "+%Y"`
month=`date "+%m"`
# assigns the dynamic URL to the URL variable like so
URL="http://images.inquirer.net/img/thumbnails/new/hea/pag/img/$year/$month/$date.jpg"
# download the image
wget -c $URL > /dev/null 2>&1
#sends the image file as a mail attachment and send it to my email box like so
echo "my email body" | mutt -s "INQ7 Front Page image subject" -a $date.jpg myemail@domain.com
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Change file access permission to be an executable bash script like so
# chmod 700 samplenews.sh
Then create a crontab job executing the script on daily basis every 7:01AM like so
01 07 * * * /myfolder/samplenews.sh > /dev/null 2>&1
That's it, a very simple approach on retrieving INQ7 front page image file every 7:01AM and deliver it into your Inbox on daily basis.
Sample image from INQ7 site:
This approach is also applicable to Abante and Tonite philippine site.
Done.
Linux commands used:
chmod, wget, bash commands, mutt, crontab
All news website are property and managed by their own respective companies and sites.
using wget for data and file transfers
Did you ever experience transferring more than 50 files from a specific site using browser?
How about downloading gigabyte files between host?
Have you ever done unattended large file transfers between hosts without monitoring it for unexpected brief disconnection or timeouts?
Have you downloaded more than 4 GB of single file from a remote host not supported by electric generators or UPS?
What about downloading multiple files on a site with different source locations, from FTP or from web with irregular filename patterns?
Most linux servers I know and all servers I have been managing boots into runlevel 3 specially those unattended servers being managed remotely from far remote locations.
With that in mind, data file transfers are done via terminal commands between two or more hosts, locally from the network or from the internet. Here are two ways to accomplish file transfer over your network and via internet.
This document entry covers data and file transfers using linux command wget. Each of them has its own set of advantages and disadvantages. And both of them have similar benefits for the users on transferring files interactively or in unattended mode. This entry aimed to maximize your systems administration time on large backup data transfers and file transfers locally and from remote host location while being proactive, busy and effective on another separate work for another hundreds of server.
USING WGET FOR FILE TRANSFERS
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Man wget:
Wget is a free utility for non-interactive download of files from the Web. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies.
Wget is non-interactive, meaning that it can work in the background, while the user is not logged on. This allows you to start a retrieval and disconnect from the system, letting Wget finish the work. By contrast, most of the Web browsers require constant user’s presence, which can be a great hindrance when transferring a lot of data.
Wget can follow links in HTML and XHTML pages and create local versions of remote web sites, fully recreating the directory structure of the original site. This is sometimes referred to as ‘‘recursive downloading.’’ While doing that, Wget respects the Robot Exclusion Standard (/robots.txt). Wget can be instructed to convert the links in downloaded HTML files to the local files for offline viewing.
WGET USAGE
~~~~~~~~~~
Transfer 4GB of file from website
# wget http://website.com/folder/bigisofile.iso
While downloading bigisofile.iso, suddenly, the remote host server went kaput due to power failure and came back after 30 minutes. Resume a partially downloaded file using wget like so
# wget -c http://website.com/folder/bigisofile.iso
Any interrupted downloads due to network and/or disconnection failure would be resumed and retried as soon as the connectivity is re-established using the wget argument -c
If a partially downloaded file exists from current folder, and wget was issued without -c , wget would continue downloading but saving the file on a differnt name like bigisofile.iso.1.
You cal also specify the number for wget retry thresholds by using the wget argument --tries. Below specified 10 retries before deciding to quit the wget.
# wget -c --tries=10 http://website.com/folder/bigisofile.iso
or
# wget -c -t 10 http://website.com/folder/bigisofile.iso
You can also apply the command above with FTP, HTTP and other retrieval protocols done from proxies like so
# wget -c --tries=10 ftp://website.com/folder/bigisofile.iso
For visual downloading of file using wget, you can issue it like o
# wget -c --progress=dot http://website.com/folder/bigisofile.iso
Rate limiting is also possible with wget using --limit-rate as an argument like so, which limits wget download rate to 100.5K per second
# wget -c --limit-rate=100.5k http://website.com/folder/bigisofile.iso
alternatively, wget limit rate of 1MB, it would be like so
# wget -c --limit-rate=1m http://website.com/folder/bigisofile.iso
Wget supports http and ftp authentication mechanism as well and can be used like so
# wget -c --user=user --password=passwd http://website.com/folder/bigisofile.iso
This can be overridden with alternative argument like so
# wget -c --user=ftp-user --password=ftp-passwd ftp://10.10.0.100/file.txt
# wget -c --user=http-user --password=http-passwd http://10.10.0.100/file.txt
Wget command can also be used on posting data to sites with cookies like so
# wget --save-cookie cookies.txt --post-data 'name=ben&passwd=ver' "http://localhost/auth.php"
And after a one time authentication with cookies shown above, we can now proceed to grab the files we want to retrieve like so
# wget --load-cookies cookies.txt -p http://localhost/goods/items.php
Recursion with wget is also supported. If you wish to download all files from a site recursively using wget, this can be done like so
# wget -r "http://localhost/starthere/"
Recursive with no directories creation is also possible. This approach downloads only the files and does not create recursive directories locally
# wget -r -nd "http://localhost/starthere/"
Retrieve the first two levels or more with wget is possible like so
@ wget -r -l2 "http://localhost/starthere/"
File globbing are also being supported by wget. File globbing special characters includes * ? [ ] . Here are more samples of wget with file glob arguments
# wget http://localhost/*.txt
# wget ftp://domain.com/pub/file??.vbs
# wget http://domain.com/pub/files??.*
# wget -r "*.jpg" http://domain.com/pub/
Absolute path for document link conversion is also being supported by wget to make local viewing possible using the downloaded files and images. This is possible using -k .
Log file is another nice feature we can get from wget by using -o like so
# wget -c -o /var/log/logfile http://localhost/file.txt
Running wget in background can be specified via wget or by bash shell same like running applications in background like so
# wget -b http://localhost/file.txt
or
# wget http://localhost/file.txt &
Wget is capable of reading URL files from files. This approach makes wget to function in batch mode like so
# wget -i URL-list.txt
The above argument does not expect any source URL from command line anymore.
Any values for retry timeouts, network timeouts, dns time outs using wget can also be defined explicitly like so
network time outs with wget specified for 3 seconds
# wget -T=3 URL
DNS time outs with wget specified for 3 seconds
# wget --dns-timeout=3 URL
Connect time outs with wget specified for 3 seconds
# wget -connect-timeout=3 URL
Read timeout with wget for 3 seconds
# wget -read-timeout=3 URL
Sleep between retrieval with wget can also be specified like so
# wget -w 3 URL
Forice wget to use IPv6 or IPv4 is done with arguments -6 and -4 respectively.
Disabling cache and cookies can be done with wget arguments using --no-cache and --no-cookies
Proxy authentication can also be supplied with wget using --proxy-user and --proxy-password like shown below
# wget --proxy-user=user --proxy-password=passwd URL
Additionally, HTTPS (SSL/TLS) are also being supported by wget using more arguments shown below. Words shown in brackets are the choices available for particular wget argument, and file refers to physical file and folder refers to physical folder
location locally.
--secure-protocol= (auto,SSLv2,SSLv3, TLSv1)
--certificate=client_certificate_file
--certificate-type= (PEM,DER)
--private-key=private_key_file
--private-key-type= (PEM,DER)
--ca-certificate=certificate_file
--ca-directory=directory_source
--no-parent needs to be specified when doing recursive wgets so as to avoid recursive search from parent directory
You can also redirect output to files by using pipe or linux redirection characters.
Happy wget!
BibleTime - Bible study from Linux howto
Well.
Linux is not only for techies as well all know, there are lot of reasons why.
Here is one reason why.
Do you like reading?
Are you interested on more reading without flipping any book pages?
How about reading with sigle tick of putting a bookmark?
Do you like reading about history, time and people?
Do you enjoy long word reading from your screen?
Do you like reading offline pages?
If so, read on.
Do you wish to study and read more of Bible scriptures from your Linux?
If so, here's a quick guide on how to install BibleTime.
BibleTime is a Bible study application for Linux. It is based on the K Desktop Environment and uses the Sword programming library to work with Bible texts, commentaries, dictionaries and books provided by the Crosswire Bible Society. BibleTime can run with GNOME too. You can install it using yum anytime as it also comes with GNU license.
BibleTime is available in several languages too. All of the language translation all listed on our translations page. The translations are available in the package bibletime-i18n. BibleTime FAQs can be seen from here.
Bibletime intergraded environment supports a full featured reading pane, full featured search tool, bookmarks and shortcut keys, viewing pane and toolbar customizations for multiple page viewing, display fonts and sizes are also included with the options. BibleTime currenly supports more than 30 major languages around and still currently expanded.
BibleTime also allows you to save the current viewpoint and pages currently being viewed before closing the application.
Quick installation.
INSTALLATION:
~~~~~~~~~~~~~~
# yum -y install bibletime
Yum installation would download around 2MB of package files and dependencies.
USAGE AND PROGRAM LAUNCH: Ctrl+F2, bibletime
During application startup, Bibletime initially prompts for remote installation of the remaining package and bible works from web to complete its software installation. From here, you can now specify and choose from which destination folder you wish to save it. Bookshelf files would be downloaded from Sword's remote site via FTP by clicking Connect to library as shown below:

At this point, you can optionally select your choice of language together with the downloads of remaining Bibletime works. Clicking Connect to Library button downloads all the remaining packages and language modules you have selected. This would take some time on slow connection. 
Bookshelf now then downloads your selected choice of language and additional bookshelf works from the web as shown below. This would not take time if you have a fast or broadband connection.
Furthermore, BibleTime prompts for optional configuration as shown below. A few of the configurable options you can choose from are BibleTime hotkeys, language module packs and display setup. You can get back from this option windows after successful installation.
Proceed by clicking Apply and OK for any changes made.
Finally, below is a running screenshot that shows two specific sections I personally chose from the BibleTime works. This sections have been tiled for wider and larger view of my screen.
One from Genesis 1:1 -
In the beginning God made the heaven and the earth. 2 But the earth was unsightly and unfurnished, and darkness was over the deep, and the Spirit of God moved over the water. 3 And God said, Let there be light, and there was light.
And another one from Revelation of John 1:1
[The] revelation of Jesus Christ, which God gave to Him to show to His slaves what [things are] necessary to occur with quickness. And He made [it] known, having sent through His angel to His slave John,
2 who testified to the word of God and to the testimony of Jesus Christ, as many [things] as he also saw.
3 ¶ Happy [or, Blessed] is the one reading [to the assembly] and the ones hearing the words of the prophecy and keeping [or, obeying] the [things] having been written in it, for the time [is] near!
Enjoy and cheers.
human readable DVD/CD drive technical details
Getting a brief and more verbose details of your DVD/CD drive technical data is not really simple to understand and interpret.
This blog entry provide more information incase you are currently experiecing DVD/CD drive linux detection or even DVD/CD drive malfunctioning. There's an instance wherein your currently detected DVD/CD drive is mishaving or malfunctioning. INt in a way it is not doing what it is expected to do.
Here's a quick linux command to retrieve DVD/CD drive details.
USAGE
~~~~~~
# cd-drive
Here's a long list of technical data shown in a human readable form.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The driver selected is GNU/Linux
The default device for this driver is /dev/cdrom
Drivers available...
GNU/Linux ioctl and MMC driver
cdrdao (TOC) disk image driver
bin/cuesheet disk image driver
Nero NRG disk image driver
CD-ROM drive supports MMC 3
Drive: /dev/cdrom
Vendor : LITE-ON
Model : DVD SHD-16P1S
Revision : GS03
Profile List Feature
Read only DVD
Core Feature
ATAPI interface
Morphing Feature
Operational Change Request/Notification not supported
Synchronous GET EVENT/STATUS NOTIFICATION supported
Removable Medium Feature
Tray type loading mechanism
can eject the medium or magazine via the normal START/STOP command
can be locked into the Logical Unit
Random Readable Feature
Multi-Read Feature
CD Read Feature
C2 Error pointers are supported
CD-Text is supported
DVD Read Feature
DVD+RW Feature
DVD+R Feature
DVD+R Double Layer Feature
Initiator- and Device-directed Power Management Feature
CD Audio External Play Feature
SCAN command is not supported
audio channels can be muted separately
audio channels can have separate volume levels
256 volume levels can be set
Ability for the device to accept new microcode via the interface Feature
Ability to respond to all commands within a specific time Feature
Ability to perform DVD CSS/CPPM authentication via RPC Feature
CSS version 1
Ability to read and write using Initiator requested performance parameters Feature
Vendor-specific code 10b Feature
Hardware : CD-ROM or DVD
Can eject : Yes
Can close tray : Yes
Can disable manual eject : Yes
Can select juke-box disc : No
Can set drive speed : No
Can read multiple sessions (e.g. PhotoCD) : Yes
Can hard reset device : No
Reading....
Can read Mode 2 Form 1 : Yes
Can read Mode 2 Form 2 : Yes
Can read (S)VCD (i.e. Mode 2 Form 1/2) : Yes
Can read C2 Errors : Yes
Can read IRSC : Yes
Can read Media Channel Number (or UPC) : Yes
Can play audio : Yes
Can read CD-DA : Yes
Can read CD-R : Yes
Can read CD-RW : Yes
Can read DVD-ROM : Yes
Writing....
Can write CD-RW : No
Can write DVD-R : No
Can write DVD-RAM : No
Can write DVD-RW : No
Can write DVD+RW : No
CD-ROM drive supports MMC 3
Drive: /dev/dvd
Vendor : LITE-ON
Model : DVD SHD-16P1S
Revision : GS03
Profile List Feature
Read only DVD
Core Feature
ATAPI interface
Morphing Feature
Operational Change Request/Notification not supported
Synchronous GET EVENT/STATUS NOTIFICATION supported
Removable Medium Feature
Tray type loading mechanism
can eject the medium or magazine via the normal START/STOP command
can be locked into the Logical Unit
Random Readable Feature
Multi-Read Feature
CD Read Feature
C2 Error pointers are supported
CD-Text is supported
DVD Read Feature
DVD+RW Feature
DVD+R Feature
DVD+R Double Layer Feature
Initiator- and Device-directed Power Management Feature
CD Audio External Play Feature
SCAN command is not supported
audio channels can be muted separately
audio channels can have separate volume levels
256 volume levels can be set
Ability for the device to accept new microcode via the interface Feature
Ability to respond to all commands within a specific time Feature
Ability to perform DVD CSS/CPPM authentication via RPC Feature
CSS version 1
Ability to read and write using Initiator requested performance parameters Feature
Vendor-specific code 10b Feature
Hardware : CD-ROM or DVD
Can eject : Yes
Can close tray : Yes
Can disable manual eject : Yes
Can select juke-box disc : No
Can set drive speed : No
Can read multiple sessions (e.g. PhotoCD) : Yes
Can hard reset device : No
Reading....
Can read Mode 2 Form 1 : Yes
Can read Mode 2 Form 2 : Yes
Can read (S)VCD (i.e. Mode 2 Form 1/2) : Yes
Can read C2 Errors : Yes
Can read IRSC : Yes
Can read Media Channel Number (or UPC) : Yes
Can play audio : Yes
Can read CD-DA : Yes
Can read CD-R : Yes
Can read CD-RW : Yes
Can read DVD-ROM : Yes
Writing....
Can write CD-RW : No
Can write DVD-R : No
Can write DVD-RAM : No
Can write DVD-RW : No
Can write DVD+RW : No
CD-ROM drive supports MMC 3
Drive: /dev/scd0
Vendor : LITE-ON
Model : DVD SHD-16P1S
Revision : GS03
Profile List Feature
Read only DVD
Core Feature
ATAPI interface
Morphing Feature
Operational Change Request/Notification not supported
Synchronous GET EVENT/STATUS NOTIFICATION supported
Removable Medium Feature
Tray type loading mechanism
can eject the medium or magazine via the normal START/STOP command
can be locked into the Logical Unit
Random Readable Feature
Multi-Read Feature
CD Read Feature
C2 Error pointers are supported
CD-Text is supported
DVD Read Feature
DVD+RW Feature
DVD+R Feature
DVD+R Double Layer Feature
Initiator- and Device-directed Power Management Feature
CD Audio Exte
rnal Play Feature
SCAN command is not supported
audio channels can be muted separately
audio channels can have separate volume levels
256 volume levels can be set
Ability for the device to accept new microcode via the interface Feature
Ability to respond to all commands within a specific time Feature
Ability to perform DVD CSS/CPPM authentication via RPC Feature
CSS version 1
Ability to read and write using Initiator requested performance parameters Feature
Vendor-specific code 10b Feature
Hardware : CD-ROM or DVD
Can eject : Yes
Can close tray : Yes
Can disable manual eject : Yes
Can select juke-box disc : No
Can set drive speed : No
Can read multiple sessions (e.g. PhotoCD) : Yes
Can hard reset device : No
Reading....
Can read Mode 2 Form 1 : Yes
Can read Mode 2 Form 2 : Yes
Can read (S)VCD (i.e. Mode 2 Form 1/2) : Yes
Can read C2 Errors : Yes
Can read IRSC : Yes
Can read Media Channel Number (or UPC) : Yes
Can play audio : Yes
Can read CD-DA : Yes
Can read CD-R : Yes
Can read CD-RW : Yes
Can read DVD-ROM : Yes
Writing....
Can write CD-RW : No
Can write DVD-R : No
Can write DVD-RAM : No
Can write DVD-RW : No
Can write DVD+RW : No
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
sound-juicer - alternative audio CD ripper install
Here's a lean, clean and simple alternative on CD ripping tools particularly for multimedia and audio CDs.
sound-juicer is a lean GNOME-desktop CD ripper and GNOME player using GStreamer which aims to have a simple, clean, easy to use interface. sound-juicer has feature to save audio CDs to Ogg/vorbis format. sound-juicer currently supports encoding to several popular audio formats such as Ogg Vorbis and FLAC, additional formats can be added through GStreamer plugins.
Sound-juicer package is currently available in Debian, RedHat, Fedora, Mandrake, and Suse. You may visit the site for any additional linux distros.
INSTALLATION
~~~~~~~~~~~~
Here's how to install this audio CD ripper.
# yum -y install sound-juicer
BINARY LAUNCH:
Ctrl+F2, sound-juicer
Sample screenshot:![]()
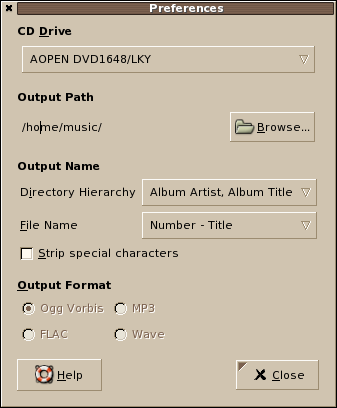
Further reading can be found here.
Stellarium - watch the sky from Linux
Stellarium is a real-time 3D photo-realistic nightsky renderer. It can generate images of the sky as seen through the Earth's atmosphere with more than one hundred thousand stars from the Hipparcos Catalogue, constellations, planets, major satellites and nebulas.
Atlast, using Fedora Linux, Stellarium awakens my long-sleeping interests and passion with stars, lunars, astronomy, skies and other sky gazing bodies of galactical space. Stellarium shows a realistic sky in 3D mode, just like what you are seeing from a naked eye, binoculars or a telescope or even from your PC. This wonderful astronomical software is way too nice not to be installed from your linux box. If you are interested with star gazing moments during weekends or Sundays, this is the time to stargazed the sky right from your fingertips!
The Stellarium software comes as an opensourced cross-platform astronomical package. Stellarium can be installed from Macs, Windows, and Linux systems. Stellarium runs smoothly to Fedora linux with small memory foorprints that gives you a more rendered day and night sky visions. You can actually adjust and select a timeframe of the day or phase of Earth's movement to be referenced as your current viewpoint. Using this Stellarium feature, viewing the sky at sunrise, sunset, midnight, or early afternoon and viewing it above the ocean, under the trees, over the moon, or even from any country location can be done easily and instantly using Stellarium.
The installation process is as easy as 1 and 2. Read more from below.
INSTALLATION:
~~~~~~~~~~~~~
# yum -y install stellarium
This would download more than 30MB of package installer.
STEALLARIUM USER GUIDES:
~~~~~~~~~~~~
Stellarium comes with separate user guide package. It contains everything you want to know with Stellarium. If you wish to install stellarium user guides, here's how to install it.
# yum -y install stellarium-doc
STELLARIUM FEATURES
~~~~~~~~~~~~~~~~~~~~~
Here are more features of Stellarium:
Features (in version 0.9.0)
* default catalogue of over 600,000 stars
* extra catalogues with more than 210 million stars
* asterisms and illustrations of the constellations
* images of nebulae (full Messier catalogue)
* realistic Milky Way
* very realistic atmosphere, sunrise and sunset
* the planets and their satellites
Interface
* a powerful zoom
* time control
* multilingual interface
* scripting to record and play your own shows
* fisheye projection for planetarium domes
* spheric mirror projection for your own dome
* graphical interface and extensive keyboard control
* telescope control
Visualisation
* equatorial and azimuthal grids
* star twinkling
* shooting stars
* eclipse simulation
* skinnable landscapes, now with spheric panorama projection
Here are sample web screenshots:

And from my own screenshots:



What are you waiting for, do the yum thing now.
Wednesday, August 29, 2007
Munin - monitor linux hosts install howto
How to monitor server and client hosts using munin?
How to install munin as graph server and as client node host?
How to configure munin as a server and as a client?
How to graph data and statistics using munin in linux?
How to have MRTG-like monitoring graph in linux?
Munin is a highly flexible and powerful solution used to create graphs of virtually everything imaginable throughout your network, while still maintaining a rattling ease of installation and configuration.
This package contains data grapher that gathers data. You will only need one instance of it in your network. It will periodically poll all the nodes in your network it's aware of for data, which it in turn will use to create graphs and HTML pages, suitable for viewing with your graphical web browser of choice.
Munin can run in two monitoring modes, as a munin graph server watching current host from where it is currently installed, or a munin node being monitored by munin grap server.
Munin is written in Perl, and relies heavily on Tobi Oetiker's excellent RRDtool. Munin generates apache graph using this RRDTool. Munin also supports API plugins feature which currently are still being enhanced.
This entry covers Munin installation and configuration guides for Fedora 7 to monitor a host. This steps should work fairly fine with later Fedora versions and CentOs 4.x versions.
By default munin installation, munin can monitor and graph the following:
a. Filesystem usage on daily and weekly graph
b. Inode usage on daily and weekly graph
c. IOStat usage on daily and weekly graph
d. MySQL throughput on daily and weekly graph
e. MySQL queries on daily and weekly graph
f. MySQL slow queries on daily and weekly graph
g. MySQL threads on daily and weekly graph
i. Network interfaces usage, traffic and error statistics on daily and weekly graph
j. Netstat usage on daily and weekly graph
k. NFS server usage on daily and weekly graph
l. Postfix mail queue on daily and weekly graph
m. Fork rate usage on daily and weekly graph
n. VMStat usage on daily and weekly graph
o. System process on daily and weekly graph
p. Sendmail mail queue, mail traffic, email volumes on daily and weekly graph
q. CPU usage, entropy, interrupts, context switches on daily and weekly graph
r. Load average, memory usage, file table usage on daily and weekly graph
s. Inode table, swap Ins/Outs usage on daily and weekly graph
and more plugins to come!
INSTALLATION STEPS
==================
MUNIN GRAPH (SERVER) INSTALLATION MODE
------------------------------------
If you wish to install munin as a stand-alone munin graphing server and gather data only from where it would be installed, simply do the below munin graph server installation like so
# yum -y install munin
MUNIN NODE (CLIENT) INSTALLATION MODE
------------------------------------
But if you wish that your other host or node be monitored by a munin graph server, you need to install munin-node on that client host like so
# yum -y install munin-node
Doing the below installation for the munin graph server like so
# yum -y install munin munin-mode
would be just fine.
MUNIN GRAPH SERVER CONFIGURATION
--------------------------
After successful yum munin server installation, take note that this munin package
a. creates /var/www/html/munin folder as default munin home page folder
b. creates /etc/munin/* folder and configuration files
c. creates munin user account with /sbin/nologin shell
d. create a cronjob in /etc/cron.d/munin
e. does not open port 4949 from current linux firewall
And it creates a default /etc/munin/munin.conf values like show below
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
dbdir /var/lib/munin
htmldir /var/www/html/munin
logdir /var/log/munin
rundir /var/run/munin
tmpldir /etc/munin/templates
[localhost]
address 127.0.0.1
use_node_name yes
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Using the above values is enough for munin to act as a graph server from where it was installed.
http://host-ip-address/munin/
Munin creates graph in per second values, if you wish to modify it and change it for per minute,you need to edit /etc/munin/munin.conf and uncomment this line
graph_period minute
You need to allow the IP address where the munin graph server is running and add it to /etc/munin-node.conf. This can be done by adding
allow ^123\.123\.123\.1233$
assuming your munin graph server has an IP address of 123.123.123.123 .
Editing /etc/munin/munin-node.conf and adding the IP address of munin graph server should be done from all host of munin node client installation.
It is assumed here that both your crontab utility and apache web server services are currently running without any problems.
Now, follow the next steps
# chown munin.munin /var/www/html/munin -R
Restart your apache and crontab utility from munin grap server like so
# service httpd restart ; service crond restart
and restart the munin from the node host like so
# service munin-node restart
Give it some time for like 5 minutes and fire up your fave browser and point it to http://host-ip-address/munin/.
The browser should be able to show you the recently generated graph.
ADD NEW MUNIN CLIENT
~~~~~~~~~~~~~~~~~~~~
If you wish to add more host nodes to be included with munin graph server, launch your fave editor and edit /etc/munin/munin.conf from the munin graph server. Add the new host node like so
[newnode.domain.com]
address 192.168.0.154
user_node_name yes
Make sure you have added the IP address of munin graph server from /etc/munin/munin-node.conf from all munin node client hosts.
If your munin client host has more than one IP address and you wish to bind munin-node in one interface only, you can edit the line
host *
from /etc/munin/munin-node.conf and put your selected ethernet IP address.
If you wish to change the port number where munin will fetch and listen for stats, this can also be done by editing
port 4949.
Make sure your that this TCP port is open from current firewall settings of all munin node client.
Restart munin-node service and firewall from munin node clients like so
# service munin-node restart
# service iptables restart
Make sure all munin node hosts are network reachable by the munin graph server.
And you're done.
See my sample screenshots:


blocking yahoo chat messenger
A very old tip and trick on blocking yahoo chat messenger from connecting to internet, as per request.
Considering an approved management policies, there are several ways to block yahoo chat messenger from connecting to internet coming from inside your network, depending on what equipment and boxes you have on ground.
If you happen to have an approved global policy to totally block yahoo messenger from any internal systems, you can implement a network-wide blocking of yahoo chat messenger at the router level.
But if you happen not to have core routers from your network and your current connection is just being shared and NATted via your linux proxy box, blocking yahoo chat messenger is easy and possible by implementing it proxy-wide or individually per IP using linux proxy and firewall.
Firewall comes in many names in linux. With Fedora, the name of the firewall is called iptables by default, a successor long after ipchains reigned with RedHats.
If you are going to block yahoo chat messenger or any software from connecting to the web, basically, gathering port numbers and protocols being used by yahoo chat messenger or by that specific software needs to be established and listed out first.
Here are the known yahoo chat messenger (YM) ports
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
TCP Port 5050
TCP Port 5000-5001
UDP Port 5000-5010
TCP Port 5100 (webcam)
TCP Port 5101 (p2p)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Blocking all yahoo chat servers is not advisable as some company IT infrastructures make use of clustered servers with round-robin and/or load-balancing approach for these ports and/or web services requests from end users, thus new servers would not be blocked until you informed yourself immediately.
USING IPTABLES FIREWALL from Fedora
-----------------------------------
Following the port numbers and protocols mentioned above, you can append these line into your /etc/sysconfig/iptables to block YM from connectin to web via linux iptables like so
Additional lines for /etc/sysconfig/iptables
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 5000:5001 -j DROP
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 5050 -j DROP
-A RH-Firewall-1-INPUT -p udp -m udp --dport 5000:5010 -j DROP
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 5100:5101 -j DROP
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
USING SQUID from Fedora
-----------------------------------
An entry of Squid installation and setup would be done separately on another entry sooner or later. But, the above mentioned iptables YM block rules can also be defined and implemeneted into Squid access list.
If the clients are all using Squid for transparent connection, additinally the next Squid access list can also be added to /etc/squid/squid.conf. There is not further changes needed from the client PC.
Additional lines for /etc/squid/squid.conf
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
acl YM_ports port 5100
acl YM_ports port 5101
acl YM_ports port 5050
acl YM_ports port 5000-5010
http_access deny YM_ports
http_access deny CONNECT YM_ports
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
After doing changes with your conf files, make sure you restart the said service like so
# service iptables restart
# service squid reload
USING Access List from Cisco Routers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
From router level, blocking YM can also be done using Cisco access list. Blocking by IP address, port numbers, destination and more are all possible with Cisco ACLs. Unfortunately, my apology for not listing it out here as that would not be linux related. :(
OTHER WAYS
~~~~~~~~~~~
Blocking Yahoo Chat messenger can also be done with different linux softwares like IPChains, IPCop, SquidGuard, Dansguardian and more. Additionally, this can also be done with all bandwidth control and monitoring appliances around the web.
Generally speaking, blocking YM takes TCP port numbers and protocol types. Doing it is a rule of thumb on blocking softwares from connecting to WWW.
Hope this fires up a starting point from your box, balu.
PS
Better to have this late blog reply than never, goodluck then.
Related Posts:
How To See Invisible YM Users
How To Setup Chikka SMS Messenger using Kopete Messenger
How to Install and Setup Google Chat Messenger
How To Setup Chikka SMS Messenger using GAIM Pidgin
How To Install GAIM Pidgin Messenger
How To Install KDE Kopete Messenger
How To Install AMSN Messenger
How To Setup and Install PSI Chat Messenger
Tuesday, August 28, 2007
string manipulation using cut linux command
Another way to parse and manipulate string characters is by using linux command cut.
Man page says
Cut removes sections from each line of files. Cut writes to standard output selected parts of each line of each input file, or standard input if no files are given or for a file name. An exit status of zero indicates success, and a nonzero value indicates failure.
Here are several examples of using cut linux command.
Sample 1:
Returns the first set of word marking space ' ' as a columnar separator
# who am i
returns
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
root pts/2 2007-08-27 06:23 (:0.0)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Using cut for getting the first word 'root' would be
# who am i | cut -f1 -d' '
Sample 2:
Linux /etc/passwd password file is consists of many fields like username, groupid, name, and more. The fields are normally separated by a field : (colon) . To retrieve or list down all usernames from /etc/passwd password file would be like
# cut -d: -f1 /etc/passwd
Sample 3:
By specifying space ' ' as the delimited character or field marker to separate set of words, the below sample then instructs to cut the remaining words separated by space character and to retain only words from 1st, 2nd, 7th and 8th columnar position like so
# echo "I like bayabas, I always watch sesame street." | cut -d' ' -f1,2,7,8
would have a output return of
~~~~~~~~~~~~~~~~~~~~~~~~~
I like sesame street.
~~~~~~~~~~~~~~~~~~~~~~~~~
Sample 4.
Cut can trim down phrases too by specifying the Nth positional character which needs to be retained like so
# echo "I know Linux is good." | cut -c 8-
would have a return of
~~~~~~~~~~~~~~~~~~~~~~~
Linux is good.
~~~~~~~~~~~~~~~~~~~~~~~
Sample 5.
Another string parsing example using cut is by specifying a starting point from Nth position with an ending Nth positional character point. This would be like like FROM to TO like so
# echo "I know Linux is good." | cut -c 8-12
would also have a return of
~~~~~~~~~
Linux
~~~~~~~~~
Lastly, reversing the specification of FROM and TO would be and retaining the rest of the words like so
# echo "I know Linux is good." | cut -d' ' -f3,4 --complement
We removed the 3rd and 4th field from words separated by space ' ' character. This would return
~~~~~~~~~~~~~~~
I know good.
~~~~~~~~~~~~~~~
Cheers
graphing skystream DVB receiver's Eb/No and signal strength
What is Skystream DVD receiver?
What is the OID variable ID for Eb/No and signal strength values of Skystream DVB receiver?
What are the statistical values available from Skystream DVB receiver?
How to retrieve Eb/No value from Skystream DVB satellite receiver box from linux terminal?
How to retrieve signal strength value from Skystream DVB receiver box from linux terminal?
How to retrieve statistical values from non-SNMP variable of Skystream DVB from terminal?
How to create and generate a Eb/No and signal strength MRTG graph of Skystream DVD receiver?
One telecom and satellite device that still works inside my work area is SkyStream DVB receiver. Skystream DVB receivers are box appliances that make use and boot up from a customized modified linux-based kernel. This VSAT equipment is usually inserted and plugged between satellite dish connectivity and core firewalls and/or core routers, that is if you are managing broadband satellite networks.
This document entry is here to cover and monitor statistical values fetched from Skystream media routers. Google spiders, as of this writing, failed to show these OID variables and Skystream MIB variable files for further polling Skystream's Eb/No and signal strength values particularly from EMR-1600, EMR-5000, and EMR-5500 Skystream DVB receiver models.
SkyStream DVB Receiver Statistical Values
==========================================
Sourced from DVB TOC file.
The Satellite Receiver statistics page shows information gathered from the unicast and multicast streams forwarded to the EMR from the Satellite Receiver. The Satellite Receiver page contains the following information:
* LNB Mode: Shows current mode as None, Single, or Dual.
* L-Band Frequency: Shows the L-Band frequency setting for the tuner.
* 22kHz Switch: Shows if 22kHz Switch is enabled, disabled or set to automatic.
* Symbol Rate: Shows the number of symbols per second being received through the tuner. This parameter can be set in Preferences as either megasymbols or kilosymbols.
* LNB Voltage Control (polarization): Shows if the polarization is set to Vertical Right or Horizontal Left.
* LNB Offset: Displays the frequency offset of the LNB in megahertz.
* Viterbi Rate: Indicates the Forward Error Correction (FEC) ratio of payload bits to the total number of bits. For example, if FEC=3/4, then for every 4 bits, 3 bits are actual data and 1 bit is overhead for error correction.
* Channel Bit Rate: Shown as Mbps— "useful bandwidth" is a calculation using the following formula; symbol rate x 2 x viterbi rate 188/204.
* QSPK Spectral Inversion: Shows as "Normal-Not Inverted" or "Inverted" this is automatically detected from the signal.
* Signal Lock (QPSK Lock): A green bar with the word LOCK will appear when the frequency and symbol rate are locked. If the signal cannot be locked, the bar will be grayed out.
NOTE For some models, BPSK or QBSK can be selected from Maintenance—Preferences, Advanced Preferences.
* Data Lock (FEC Lock): A green bar with the word LOCK will be displayed if Symbol Rate, L-Band Frequency, and FEC are set properly. If data cannot be locked, a red bar is displayed with the words "NO LOCK" in the bar.
* MPE Lock: A green bar with the word LOCK will be displayed if data with an MPE header is being received. If data cannot be locked, a red bar is displayed with the words "NO LOCK" in the bar.
* Signal Strength: Shows a value and percentage for the signal strength being received from the satellite (-25 dBm to -65 dBm).
* Eb/N0: Displays the signal to noise ratio value detected by the Satellite Receiver in decibels.
* QPSK Bit Error Rate: Displays the measured QPSK bit error rate.
* Viterbi Bit Error Rate: Displays the measured error rate from the FEC algorithm.
* Reed Solomon Corrected Errors: Shows the errors that were fixed using the Reed Solomon algorithm. These errors indicate that some data was corrupted and then corrected. Errors are collected over time and will continue to build; a button is included on this page to clear the error counters.
* Reed Solomon Uncorrected Errors: Displays the total number of errors that the Reed Solomon Correction Algorithm detected but was unable to correct.
Skystream website is now part of Tandberg Television.
GOAL:
Retrieve Eb/No and signal strength values from any web-enabled satellite DVB receiver devices and media routers for further long-term graphing, analysis and monitoring.
STEPS:
A simple workaround solution using linux commands via terminal.
WORKAROUND SOLUTION WITHOUT USING SNMP:
Fireup your terminal and issue the command as follow
# elinks -dump 1 -auth=emrYOURusername:emrYOURpassword "http://YOUR-DVB-IP/cgi-bin/statistics?page=sat&session=sat"
As usual, changes needs to be done from the above shown commands:
emrYOURusername = would be admin's username
emrYOURpassword = would be admin's password
YOUR-DVB-IP = dvb's IP address
Resulting sample output:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Satellite Receiver Statistics
Parameter Satellite Receiver 1
LNB Mode None
L-Band Frequency 1000.0000 MHz
22kHz Switch Disabled
Symbol Rate 27.0047 Msymbols/s
LNB Voltage Control (polarization) Vertical - Right
LNB Offset 0.1650 MHz
Viterbi Rate 7/8
Channel Bit Rate 43.5517 Mbps
QPSK Spectral Inversion Normal - Not Inverted
Signal Lock (QPSK Lock) LOCK
Data Lock (FEC Lock) LOCK
MPE Lock LOCK
Signal Strength 72 %
Eb/N0 15.0277 dB
QPSK Bit Error Rate 0.0000
Viterbi Bit Error Rate 0.0000
Reed-Solomon Corrected Errors 0
Reed-Solomon Uncorrected Errors 7
Auto Refresh (_) Enable (_) Disable
Auto Interval ___ Sec [BUTTON] [BUTTON]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
As you can see from above, these resulting output is supposed to be viewed as HTML page from browsing the IP address of the said box.
Using this linux command lynx, we have just dumped out the page into our screen. Basically, the important numerical value that is needed here are Eb/No and signal strength values.
Now, further string manipulation command is required if you wish to get t
he numerical value of Eb/No and signal strength. String manipulation in linux can be done many ways.
Here's one way to do it. From the last issued command, you just need to append linux filtering commands grep. By piping last screen output as an input to grep would be as follows
| grep 'Eb/N0\|Signal Strength'
to make the first linux command to look like
# elinks -dump 1 -auth=emrYOURusername:emrYOURpassword "http://YOUR-DVB-IP/cgi-bin/statistics?page=sat&session=sat" | grep 'Eb/N0\|Signal Strength'
This linux compounded commands would now give us what needed most, a 2 liner output like so:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Signal Strength 72 %
Eb/N0 15.0125 dB
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If you wish to feed this values into to MRTG scripts, further string manipulation is required.
Since we already know that the first value is the signal strength and the second value is the Eb/No., we need to remove the first 40 characters of each lines. This would be done using linux command cut like so
cut -c 40-
Then, fetching the first field like so
awk '{print $1}'
Finally we would arrive to a one shot linux command on getting Skystream DVB receiver's Eb/No and signal strength values, like so
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# lynx -dump -auth=emradmin:gulaydvb "http://YOUR-DVB-IP/cgi-bin/statistics?page=sat&session=sat" | grep 'Eb/N0\|Signal Strength' | cut -c 40- | awk '{print $1}'
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Resulting output:
~~~~~~~~~~~~~~
72
15.0226
~~~~~~~~~~~~~~
which can be easily dumped to MRTG for further SNMP polling and graph generation. Using this approach, you can now graph and monitor the other Skystream DVB receivers's statistical values.
Additionally, creating graphs for skystream dvb's intel-based ethernet network cards would be simply done the normal way since ethernet cards for most appliances and boxes supports SNMP. Like shown below:
Now, google spiders can lead you to this page with regards to graphing Eb/No and signal strength from Skystream DVB receiver models.
Hope this helps.
Sunday, August 26, 2007
BZFlag - 3D multi-player tank game install howto
A very tactical nice 3D enabled multiplayer strategical linux battle tank game. The approach and skills required for this tank game appears to be similar to the strategy skills used from playing the old and famous tank game played under Nintendo boxes years ago. This nice battle tank game has much more 3D graphics and audio enhancements, runs in several OS platforms like Linux, Macs, Windows with easy installation steps. BZflag also allows you to create your own game server locally from network or even from internet game servers with customized tank and play settings.
BZFlag site describes:
BZFlag is a 3D multi-player tank battle game that allows users to play against each other in a networked environment. There are five teams: red, green, blue, purple and rogue (rogue tanks are black). Destroying a player on another team scores a win, while being destroyed or destroying a teammate scores a loss. Rogues have no teammates (not even other rogues), so they cannot shoot teammates and they do not have a team score. There are two main styles of play: capture-the-flag and free-for-all.
BZFlag is a free online multiplayer cross-platform open source 3D tank battle game. The name originates from "Battle Zone capture the Flag". It runs on Irix, Linux, *BSD, Windows, Mac OS X, and many other platforms. It's one of the most popular games ever on Silicon Graphics machines and continues to be developed and improved to this day. It's one of the most popular open source games ever. For more information, check out some of the reviews.
Easy installation steps of this multiplayer BZFlag 3D tank game. Issue the below commands
# yum -y install bzflag
Sample bzflag tank game screenshot:


Enjoy.
screenshot and snapshot creations howtos
How to create desktop screenshots from terminal?
How to create desktop screenshots from Linux X?
How to create thumbnail images of any picture file from terminal?
How to create thumbnail images of any picture file from Linux X?
How to create thumbnail screenshot of a page from terminal?
How to capture portion of the screen using Linux X?
How to capture portion of the screen using terminal?
How to resize any image file from terminal?
How to convert picture file formats from terminal?
How to convert PNG to JPG from terminal?
How to convert PNG to GIF from terminal?
How to install ImageMagick?
How to install KSnapShot?
How to create screenshots using ksnapshot?
How to create screenshots using gnome-screenshot?
Here are several ways to create desktop screenshot in Fedora Linux.
How to create desktop screenshots from terminal?
How to install ImageMagick?
# yum -y install ImageMagick
To selectively capture a portion of the screen using terminal, issue
# import test.png
# import test.jpg
and drag the mouse to select portion of the screen to be captured by import command.
A sample screenshot creation done from terminal 
To capture a 800x640 screen size of the screen using import from terminal, issue
# import -window root -geometry 800x640 test.png
To capture a 800x640 screen size after 5 seconds, simply
# sleep 5; echo Capturing screenshot... ; import -window root -geometry 1024x640 test.png
or
# import -window root -geometry 800x640 -pause 5 test.png
How to create thumbnail images of any picture file from terminal?
How to create thumbnail screenshot of a page from terminal?
How to convert an image from PNG to JPG from terminal using mogrify linux command?
How to convert an image from PNG to GIF from terminal using convert linux command?
How to resize any image file from terminal?
How to convert picture file formats from terminal?
Create a wide screen shot first
# import -window root test.png
Convert existing PNG to JPG and create a 250x90 thumbnail image at the same time
# mogrify -format jpg -auto-orient -thumbnail 250x90 test.png
Convert existing PNG to GIF and craete a 250x90 thumbnail snapshot
# convert test.png -auto-orient -thumbnail 250x90 test.gif
Sample converted thumbnail screenshot.
Create a thumbnail screenshot.
# import -window root -geometry 250x90 test.png
Sample thumbnail screenshot of an opened terminal.
How to create desktop screenshots from linux X?
Press Alt+Printscreen key to capture and create an image of the current active window.
Press Printscreen to capture and create a screenshot of the whole screen
How to install ImageMagick?
# yum -y install ImageMagick
How to install KPhotoAlbum.i386?
# yum -y install kphotoalbum.i386
How to create screenshots using ksnapshot?
How to capture screen portion/section from Linux X using ksnapshot?
How to create screenshots using ksnapshot?
How to create screen snapshots?
# ksnapshot
and choose Portion of the Screen from dropdown bar
How to create screenshots using gnome-screenshot?
# gnome-screenshot --interactive
More import readings from here.
That's it.
string parsing using bash
Unfortunately, Google doesn't know about this.
Even Google global indexes doesn't refer to any link with regards to this entry and topic. Interesting but weird.
~~~~~~~~~~~~~~~~~~~~
#!/bin/bash
var1=`ifconfig eth0`
var2=${var1#*addr:}
var2=${var2%% *}
~~~~~~~~~~~~~~~~~~~~
The output of the above bash script when executed would be the current IP address of eth0.
String parsing can be done using special bash characters as shown with the above bash script sample. The string parsing shown above can also be done directly from terminal like so
# var1=`ifconfig eth0` ; var2=${var1#*addr:} | echo ${var2%% *}
%%, % and #* are the special bash character search commands.
Now, the next question is how fast google indexes the web? I am going to measure it by publishing this post, I know Google indexes this entry so fast which I don't know why. I need to see if Google algorith can tag these characters as a bell for search queries as well.
STORY:
Before I started this blog entry. Searching Google DOES NOT give me any results from searching ANY character combinations shown below. I have searched it one line at at time and leads to ZERO result. See my search quries
"%%"
%%
"#*"
#*
##
"##"
*
#
Google index also suggested that I should remove quotes and results are all the same, NOT FOUND. I am posting my search screenshots below referring to NOT FOUND results by Google using the above search keyword.
So that we can conclude
a. If these characters are special for Google and removes them from any search keywords or character before searching global indexes.
b. After posting this entry, if Google global indexes can return something or refer to this blog entry right after several minutes of posting this? That basically means Google spiders knows these character keywords and therefor Google does not have it from their indexes before this blog entry was posted! Interesting.



Google not found search link 1, search 2, search 3,, search 4, yes google spiders failed to return results, perhaps its a special character for google algorithm as well. :)
I would edit this page back again IF and ONLY IF Google returns and crawls those special characters from this entry. And IF Google refers to this blog entry when somebody searches for those search key characters. :)
Later.

Make Money


Live Traffic
